

Firstly, what is OCR
OCR (Optical Character Recognition) stands for Optical Character Recognition, which can convert different types of documents (such as scanned paper documents, PDF files, or images captured by digital cameras) into editable data. OCR is sometimes referred to as text recognition. Generally speaking, if you want to digitize magazine articles or print files, the easiest method that comes to mind is to spend several hours re entering the document and then correcting spelling errors. The emergence of OCR technology has changed this time-consuming approach. You can use a high-speed camera (or digital camera, scanner) and optical character recognition software to convert the required document materials into editable digital formats within a few minutes.

The main advantages of OCR technology are saving time, reducing errors, and minimizing workload. You can scan paper documents for further editing and sharing with colleagues and partners. You can extract the necessary text for citation from books and magazines without the need to re-enter. How does a high-speed scanner scan and recognize WORD with OCR function?
The device currently in use is a high-speed scanner.
1. After connecting the Fenglin high-speed camera device and computer, open the Fenglin image acquisition system
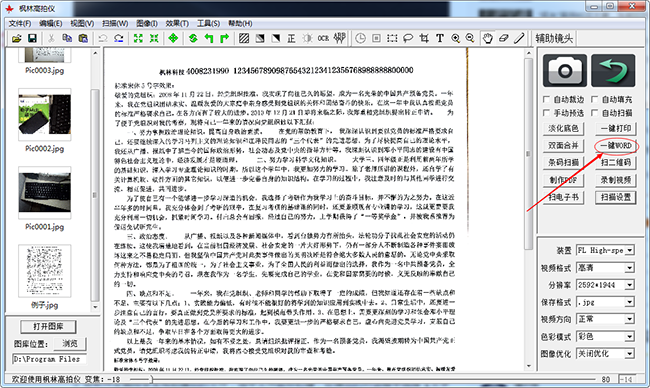
2. Place the required shooting files in the document table, take a photo, and then select and click the 【 One click WORD 】 button on the right side of the software
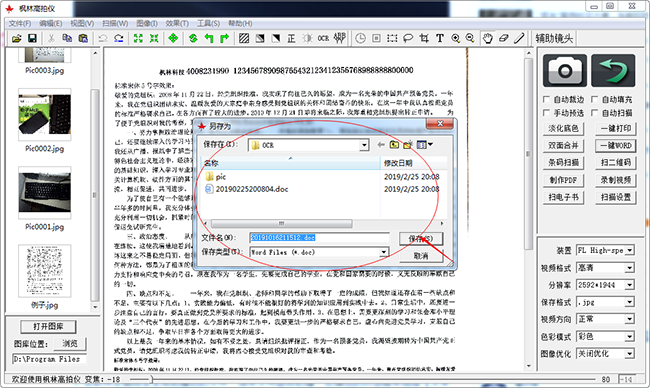
3. The software will select the desired location to save as [Save] button
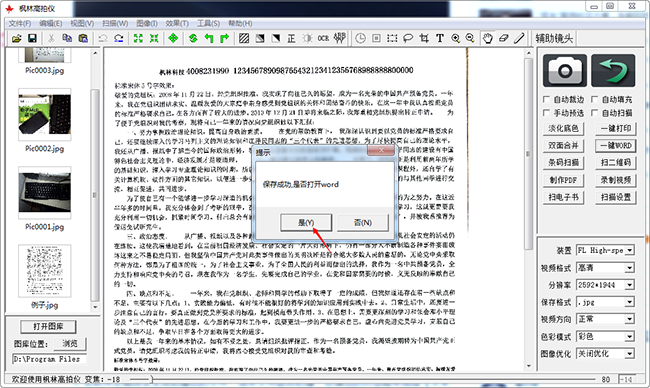
4. After successfully scanning and recognizing the text, select whether to open the "Yes" button.
5. Wait for a moment, and after the software recognizes the file successfully, the original image files in the file list will be converted into editable Word files, which can be opened to edit the file content.
Note: If you want to find the file again, please record the saved location before opening the file
By using the OCR text scanning and recognition function of the high-speed scanner equipment, the text content of the original paper document can be converted into data, and the final recognized document will look just like the original document. The whole process is fast and simple, avoiding the tedious manual input.